There are few things that get a book or theatre nerd’s heart rate up faster than the words “Shakespeare Folio” so imagine my delight when I was told I’d be scanning three of them. For those who are not familiar with what those words mean, there are four folios that were printed after Shakespeare’s death, collecting his plays, the contents vary from first to fourth, with corrections and additions, but basically what we know of his work owes a great debt to these four books printed in the 1600s. As you might guess there are not a lot of copies extant. I was excited enough that I posed with the frontispiece of the Second Folio. We also scanned two copies of the Fourth Folio; links to all are below.
There are few things that get a book or theatre nerd’s heart rate up faster than the words “Shakespeare Folio” so imagine my delight when I was told I’d be scanning three of them. For those who are not familiar with what those words mean, there are four folios that were printed after Shakespeare’s death, collecting his plays, the contents vary from first to fourth, with corrections and additions, but basically what we know of his work owes a great debt to these four books printed in the 1600s. As you might guess there are not a lot of copies extant. I was excited enough that I posed with the frontispiece of the Second Folio. We also scanned two copies of the Fourth Folio; links to all are below.
The volumes are not owned by our institution but are part of the BC Legislative Library collections, and there was a fair bit of behind the scenes negotiations to get them here. Once they were in the building it was our single highest priority to get them done. Unlike much of the material we work with, these items had to be retrieved from and returned to the vaults in Special Collections and Archives each day. This added a couple of key challenges — one of which we managed well and one of which we did not manage as well as we could have.
Key challenge number one was the timing. My shift runs from 9 am to 5 pm but the material needed to be back in the vault before 4:30 when the last staff member left from that area. In order to maximize the time we spent scanning, other staff would collect the volume before I started and would scan until I arrived and while I was on lunch or coffee breaks, or off for a flex day — the project spanned about 8 weeks in March and April 2017 — so that we could get as close as possible to 7.5 hours of scanning per day. We managed that more often than not, with a total of just under 200 hours of scan time. Adding in the setup for each book and the editing to split the pages afterward and the total time for the project was close to 225 hours.
Key challenge number two was placement of the book on the scan bed. Books are typically scanned at what looks like a right angle, the scan goes top to bottom rather than left to right — this is to minimize shadow from the lighting along the inner margin. It was critical to mark where the material sat on the scan bed so we could place it back there the next morning. We managed to get it centered in one direction by laying down a magnet bar beside it before we removed it each evening, however, we did not do as good a job centering the material the other way so that the inner margin was in the same place each scan.
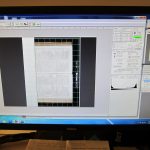
This is more difficult because as we move through the book, the way the pages lay shifts. The books are supported so that there is no stress on the binding by stacking discarded journals, topped by acid free paper; these stacks are higher or lower depending what page we are scanning. For one of the volumes there was even greater challenge because the binding was broken and pages were loose. There was probably a couple of centimeters variation left to right in final scans. Where this became a problem was post-scanning, during the cropping and page separation process, because it added a step where each page had to be cropped to center it before the batch separation could be done. As you can see in this image, simply dividing the image in two without centering would have resulted in loss of margin and in some cases loss of text:

We kept notes along the way where page numbers were printed in error, for example page 355 may have been printed as page 335, as we needed to be clear once separated which order the pages belonged in. In some cases, where it appeared pages were missing, we had to double check with existing facsimiles on the Internet Shakespeare Edition. In one case, pages were in fact missing from the copy we were scanning; in another case, the same numbering error that seemed to show a gap was reflected in the facsimile. We even found an “oops” where we’d missed a pair of pages. Luckily the material was still available for us to do replacement scans. The notes were transcribed into “ReadMe” text files for use by the staff who need to input the metadata so that these details are available to those who access the materials.
This was a particularly long project, and more stressful to me because I really do recognize the significance of these books, and the joy that we will be able to make them more widely available, and I had to hold my tongue about it for so long when all I wanted to do was tell everyone how excited I was to be working on this project. So now that the cat’s out of the bag, please do ask me what it was like to spend so much time with the Bard’s words. If you’d like to see the digital objects, links are below:
- Shakespeare’s Second folio, 1632
- Shakespeare’s Fourth Folio, 1685 [Copy 01]
- Shakespeare’s Fourth folio, 1685 [Copy 02]
More pictures from behind the scenes: