
UVic Libraries and Research Computing Services are working together to bring you a series of workshops on Reproducibility, spanning from October 2024 to February 2025.
What is reproducibility?
- Reproducible: A result is reproducible when the same analysis steps performed on the same dataset consistently produces the same answer.
Reproducibility, in the context of open access, is the practice of making your data and methods openly accessible so that other academics or scientists can use the same data and same methods to try and reproduce your results. Reproducibility is incredibly important in academia, as it helps to verify the information that’s being published and avoid the spread of misinformation. It also helps to facilitate collaboration between scholars and allows others to develop an in-depth understanding of your work.
The different dimensions of reproducible research described in the matrix above have the following definitions, as described by The Turing Way:
- Reproducible: A result is reproducible when the same analysis steps performed on the same dataset consistently produces the same answer.
- Replicable: A result is replicable when the same analysis performed on different datasets produces qualitatively similar answers.
- Robust: A result is robust when the same dataset is subjected to different analysis workflows to answer the same research question (for example one pipeline written in R and another written in Python) and a qualitatively similar or identical answer is produced. Robust results show that the work is not dependent on the specificities of the programming language chosen to perform the analysis.
- Generalisable: Combining replicable and robust findings allow us to form generalisable results. Note that running an analysis on a different software implementation and with a different dataset does not provide generalised results. There will be many more steps to know how well the work applies to all the different aspects of the research question. Generalisation is an important step towards understanding that the result is not dependent on a particular dataset nor a particular version of the analysis pipeline.
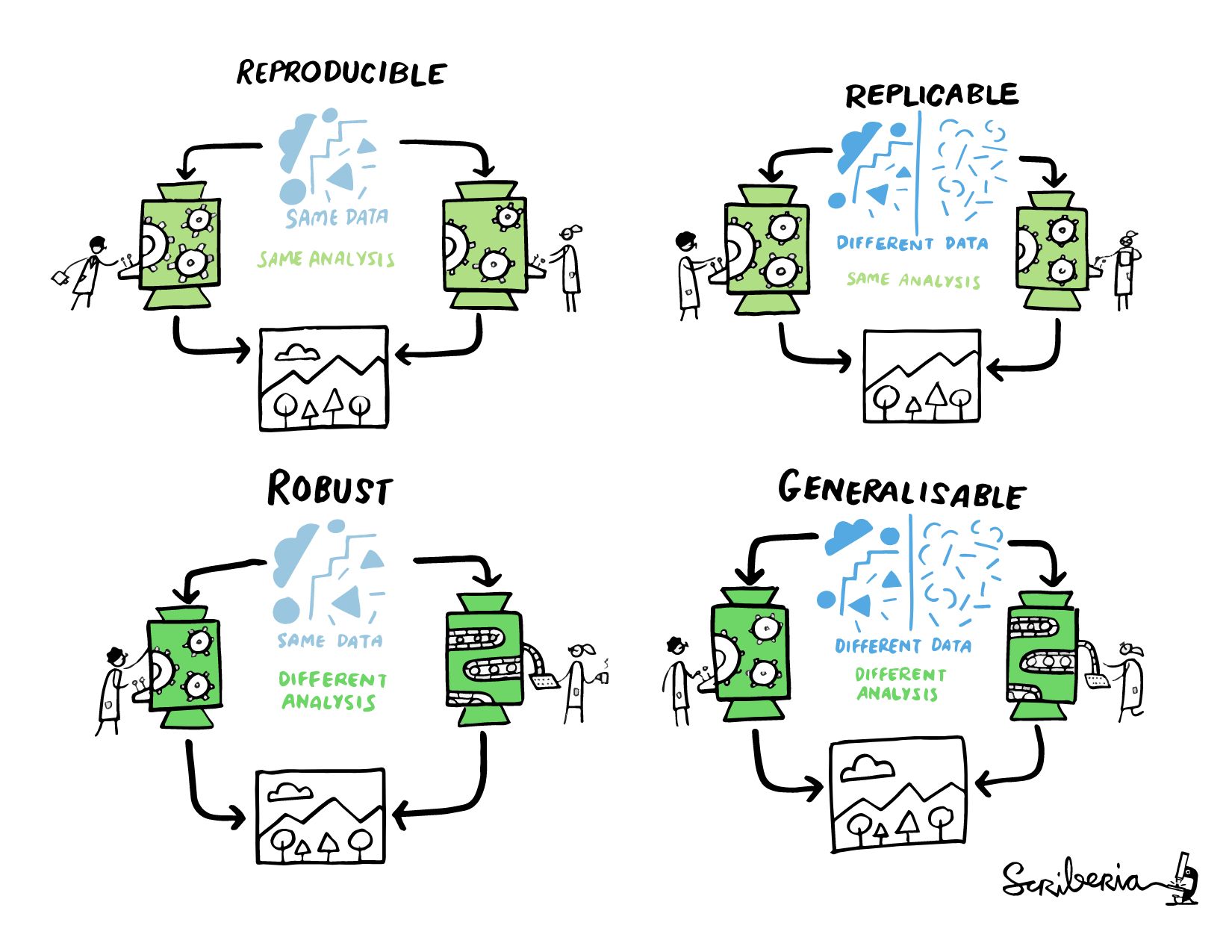
Fig. 10 The Turing Way project illustration by Scriberia.
Used under a CC-BY 4.0 licence. DOI: 10.5281/zenodo.3332807.
Workshop Schedule

